趋势可视化
简介
趋势可视化功能将msProbe工具采集的精度数据进行解析,识别其中模型层的张量目标,以及其在迭代步数、节点rank和网络模型中的位置。将张量目标的统计量数据从迭代步数step、节点rank和张量目标三个维度进行趋势可视化,方便用户从数据整体的趋势分布观测精度数据,分析精度问题。
基本概念
msProbe:全称MindStudio Probe,是精度调试工具包,可以定位模型训练或推理中的精度问题。
dump:MindStudio Probe下数据采集功能,采集的数据称为dump数据。
monitor:MindStudio Probe下训练状态监测功能,采集的数据称为monitor数据。
三个维度:趋势可视化工具中,可选的观测数据的维度,特指以下三个:迭代步数(Step)、节点(Rank)和张量目标(Module Name,主要以所属网络层或算子名进行区分)。
使用流程
使用前准备
环境准备
安装msProbe工具,详情请参见《msProbe工具安装指南》。
安装方式选择“编译安装”时,编译命令须配置参数--include-mod=trend_analyzer来构建趋势可视化插件。
数据准备
dump数据场景(采集模型数据,选择
level为L0或者mix)PyTorch框架详细采集方式请参见《PyTorch场景精度数据采集》。
MindSpore框架详细采集方式请参见《MindSpore场景精度数据采集》。
monitor数据场景(输出格式
format指定为csv)详细采集方式请参见《Monitor训练状态轻量化监测工具》。
约束
支持PyTorch框架和MindSpore框架。
精度数据解析
功能说明
解析dump数据或monitor数据,识别其中各模型层下的张量目标,根据dump数据落盘顺序确定张量目标在迭代步数、节点rank和网络模型中的位置,并将解析结果转存为db格式的SQLite数据库文件。
注意事项
dump数据: 仅支持dump配置的
level为L0或者mix级别采集的数据。monitor数据: 仅支持输出格式
format指定为csv采集的数据。为了有效呈现数据趋势,落盘数据范围为
[-1e9, 1e9],超出此范围的数据将被截断,inf值将被转换为1e9+1,-inf值将被转换为-1e9-1。
命令格式
msprobe data2db --db <db_path> --data <data_path> [--format <format>] [--mapping <mapping_json>] [--micro_step <use_micro_step>] [--process_num <process_num>]
参数说明
参数 |
可选/必选 |
说明 |
|---|---|---|
–db |
必选 |
解析结果文件存盘目录,str类型。在该目录下生成后缀为 |
–data |
必选 |
输入数据路径,str类型。支持dump数据目录或monitor数据目录。dump数据需配置到step文件夹的上一层目录,monitor数据配置到rank文件夹的上一层目录。 |
–format |
可选 |
数据格式,str类型。可选值: |
–mapping |
可选 |
指定json映射文件路径(须配置到json文件名,例如./mapping.json),str类型。程序会在解析精度数据时,将其中模型层的名称或算子名称根据映射文件做转换,以达到精简名称或step间模型或算子名称对齐的效果。映射文件详细配置请参见mapping配置文件说明。 |
–micro_step |
可选 |
是否启用微步计数,bool类型。默认值为 |
–process_num |
可选 |
并行处理进程数,int类型。默认值为1,仅用于monitor数据的并行处理加速,dump数据处理暂不支持多进程。 |
使用示例
解析/data/dump_path下的数据文件, 自动识别monitor数据和dump数据,将解析所得db格式的SQLite数据库文件放在/data/db_path路径下。单进程执行,以微迭代计数,且不使用mapping。
msprobe data2db --data /data/dump_path --db /data/db_path
输出说明
dump数据解析命令执行成功后,在/data/db_path下生成dump_data.trend.db文件。
monitor数据解析命令执行成功后,在/data/db_path下生成monitor_data.trend.db文件。
趋势分析
功能说明
趋势分析是将张量目标的统计量数据从迭代步数step、节点rank和张量目标三个维度进行可视化分析,方便用户从数据整体的趋势分布观测精度数据,分析精度问题。
界面介绍
趋势可视化构图界面如图所示,包含区域一(选择工具栏)、区域二(热力图)和区域三(折线图)。
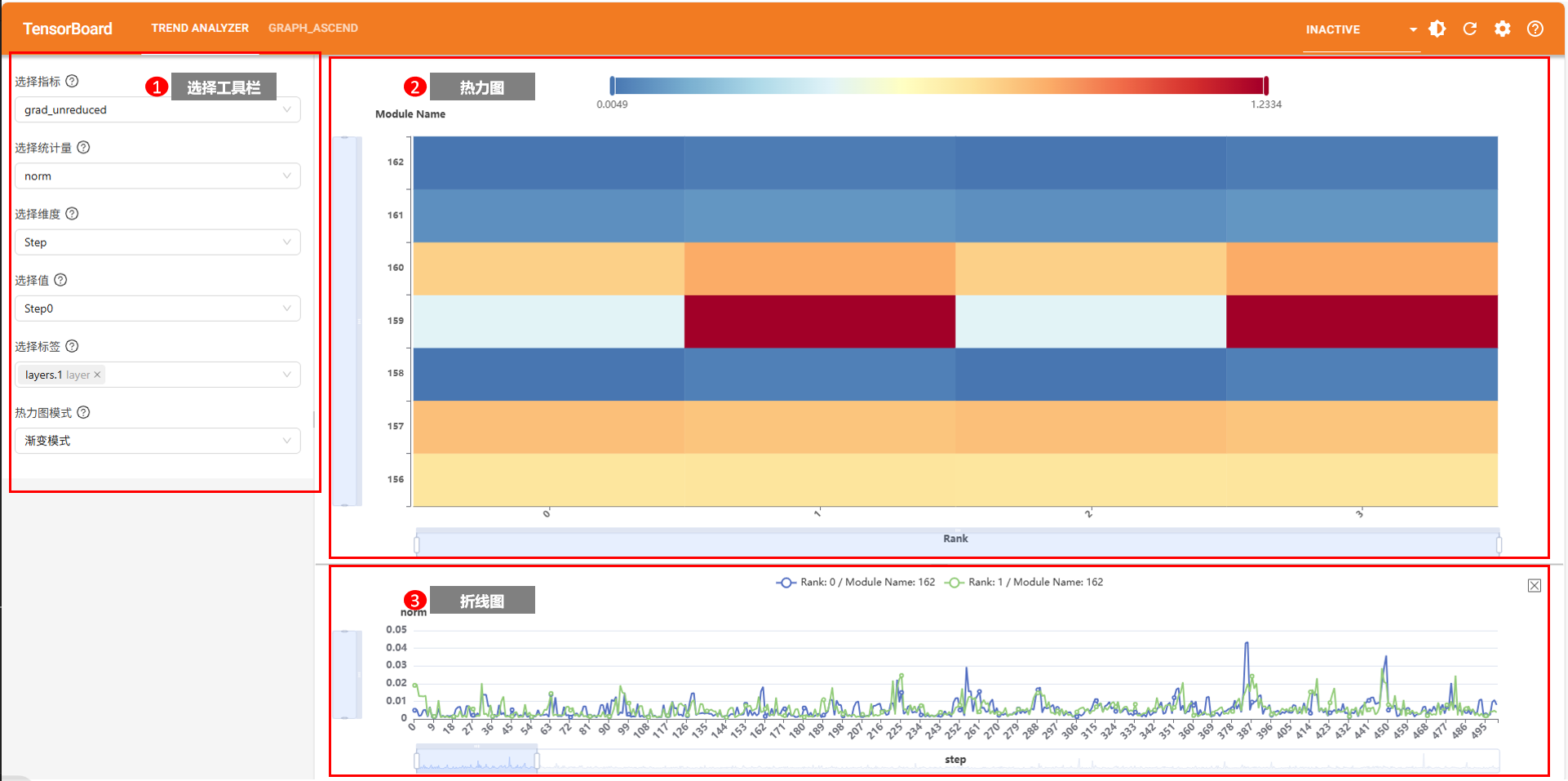
区域一:选择工具栏,依次提供指标、统计量、显示维度、维度值的选择,并提供标签筛选和热力图模式设置。
区域二:热力图,展示当前选择维度的值下,精度数据在其余两个维度上的分布热力图。
区域三:折线图,当前选择维度的值下,点击热力图中的某个点,折线图展示该点对应的精度数据随维度值变化趋势。
使用说明
启动TensorBoard
可直连的服务器
将生成.trend.db文件的路径out_path传入–logdir。
tensorboard --logdir out_path --bind_all
启动后会打印日志。

上图中,ubuntu是机器地址,6008是端口号,可以通过–port参数指定其他端口号。
说明:ubuntu需要替换为真实的服务器地址,例如真实的服务器地址为10.123.456.78,则需要在浏览器窗口输入 http://10.123.456.78:6008。
不可直连的服务器
如果链接打不开(服务器无法直连需要挂vpn才能连接等场景),可以尝试以下方法,选择其一即可。
本地电脑网络手动设置代理,例如Windows10系统,在【手动设置代理】中添加服务器地址(例如10.123.456.78)。
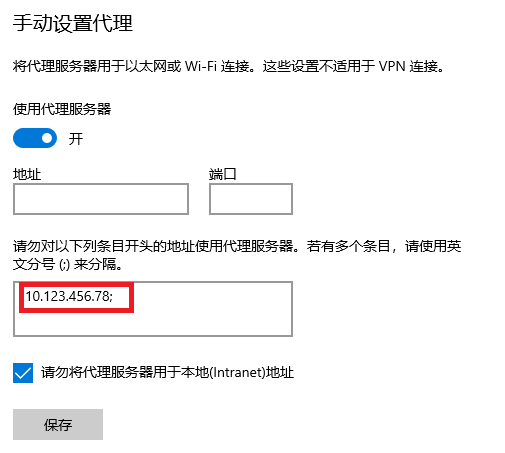
然后在服务器中输入如下命令:
tensorboard --logdir out_path --bind_all
最后,在浏览器窗口输入http://10.123.156.78:6008
说明:如果当前服务器开启了防火墙,则此方法无效,需要关闭防火墙,或者尝试后续方法。
或者使用vscode连接服务器,在vscode终端输入:
tensorboard --logdir out_path

按住CTRL点击链接即可。
或者将构图结果文件从服务器传输至本地电脑,在本地电脑中安装msProbe查看构图结果。
PC终端输入:
tensorboard --logdir out_path
按住CTRL点击链接即可。
打开浏览器界面
推荐使用谷歌浏览器,按下图操作进入趋势可视化构图页面:
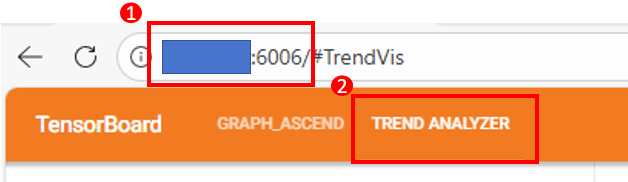
在浏览器中输入机器地址+端口号回车,出现TensorBoard页面。
点击左上方的
TREND ANALYZER,进入趋势可视化构图页面。
多数据库文件支持
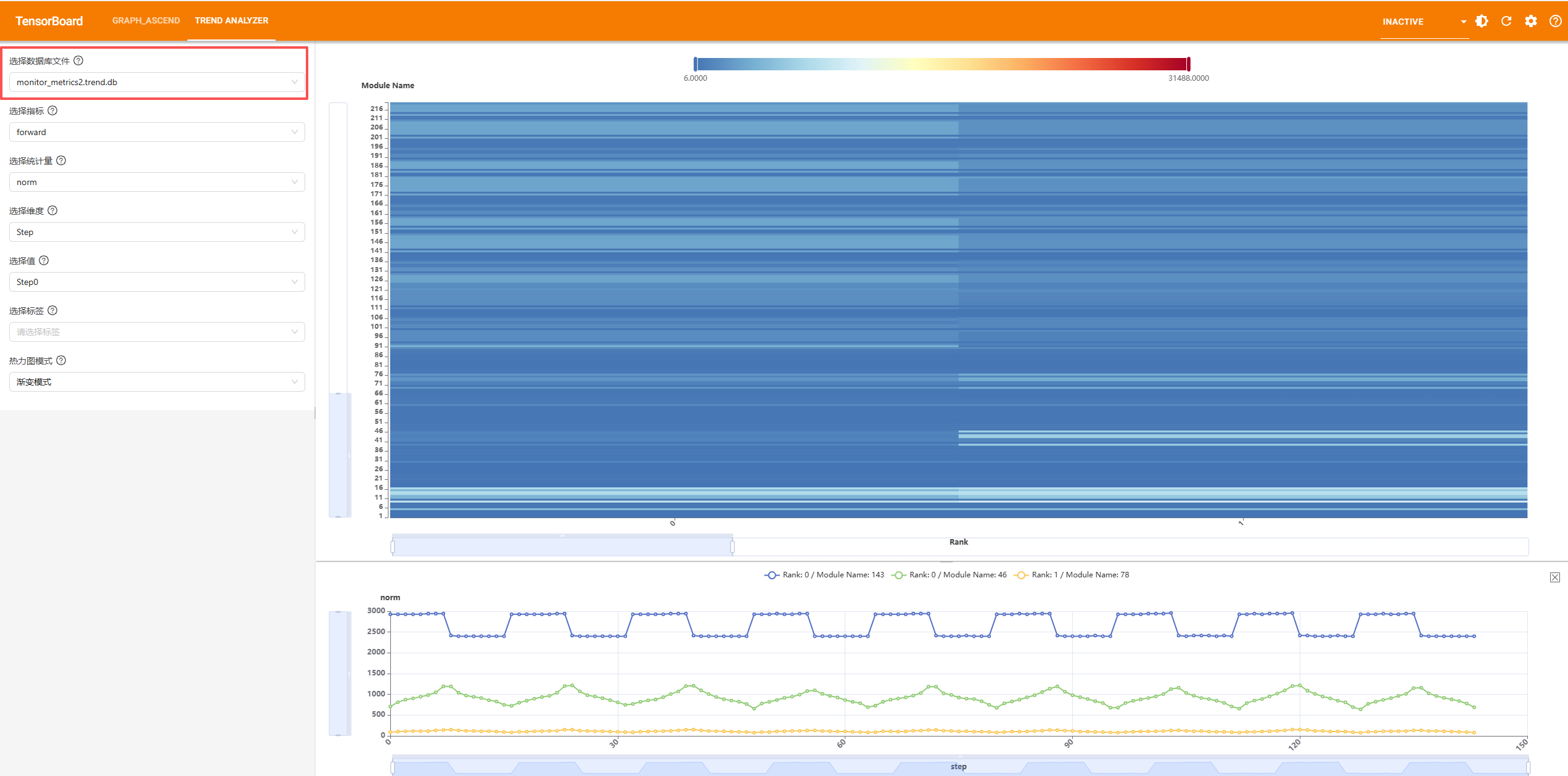
本插件支持扫描和切换多个 .trend.db 数据库文件。
功能特性
自动扫描: 插件启动时会自动扫描 logdir 目录下所有的
.trend.db文件。动态切换: 通过前端下拉框可以实时切换到不同的数据库文件。
自动刷新: 切换数据库后页面会自动刷新,展示新数据库的数据。
使用方法
准备多个数据库文件
在 TensorBoard 的 logdir 目录下放置多个
.trend.db文件,例如:logdir/ ├── experiment1.trend.db ├── experiment2.trend.db └── experiment3.trend.db
选择数据库文件
打开浏览器访问
http://localhost:6006。选择顶部导航栏的“Trend Analyzer”标签页。
在左侧控制面板中,找到“选择数据库文件”下拉框。
从下拉列表中选择要查看的数据库文件。
页面会自动刷新并展示所选数据库的数据。
注意事项
数据库文件必须以
.trend.db为后缀。切换数据库会触发页面刷新,当前选择的指标、维度等配置会被重置。
如果没有找到任何
.trend.db文件,插件将不会激活。
展示热力图
通过选择工具栏中的指标、统计量、显示维度和维度值,即可展示当前维度值下,精度数据在其余两个维度上的分布热力图。界面如图所示,具体操作如下表所示。
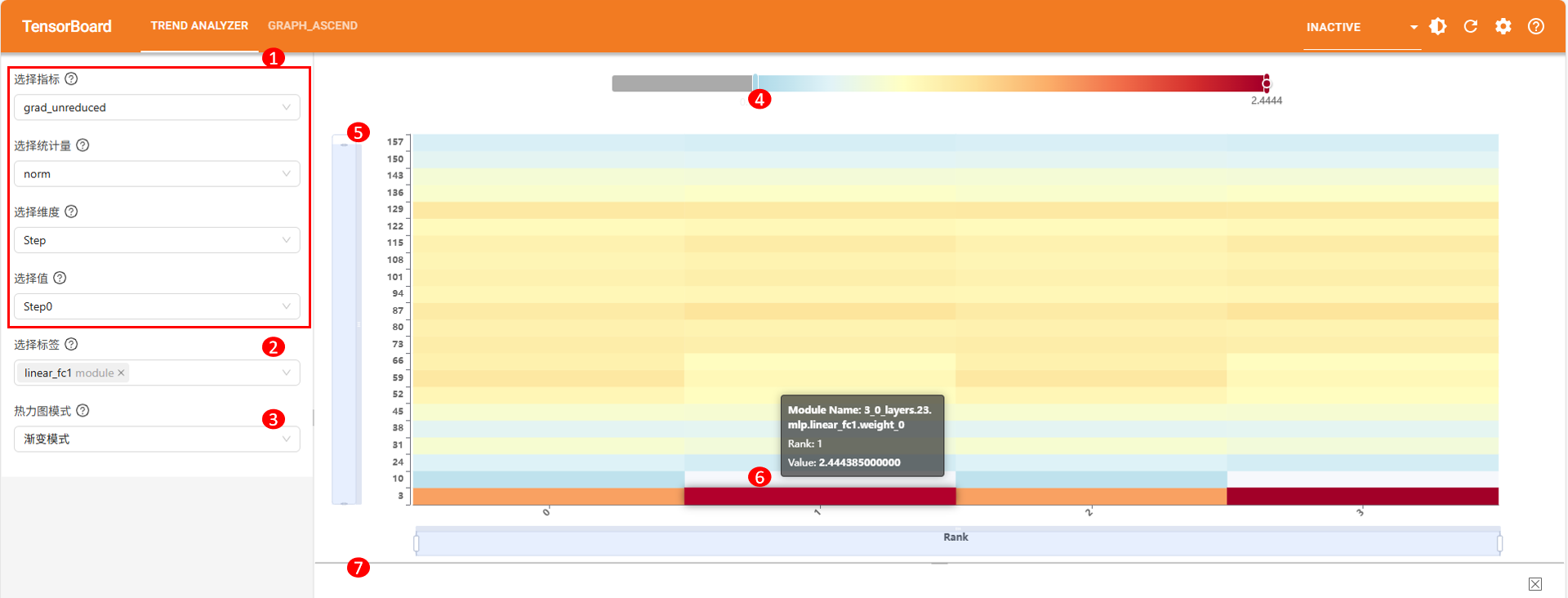
编号 |
说明 |
|---|---|
1 |
选择需要展示数据基本范围,依次选择指标、统计量、维度和维度值,具体见选择参数范围 。选择完毕即会加载对应热力图。 |
2 |
可选,点击选择标签,在下拉框中选择或输入需要筛选的标签值,通过标签筛选仅显示相关Module Name的数据。可多选,标签类型见选择参数范围。 |
3 |
可选,点击热力图模式下拉框,切换为渐变模式或分段模式。 |
4 |
可选,拖动热力条,调整热力图展示的数值范围。 |
5 |
可选,拖动热力图X轴或Y轴上滑块,调整热力图展示的坐标轴范围。 |
6 |
可选,悬浮在热力图上,展示当前鼠标位置数据块的具体信息。 |
7 |
可选,拖动热力图与折线图分割线,调整热力图占页面比例。 |
当选择维度为Step时,如果是Megatron模型并行场景,可以使用Megatron模型并行可视化对照理解各个rank下采集的网络层数据与实际整网位置对应关系。
选择范围 |
说明 |
|---|---|
指标 |
dump数据场景: |
统计量 |
• dump数据场景: 固定为 “norm”、“max”、“mean”、“min”,分别表示2范数、最大值、均值、最小值。 |
维度 |
包含以下可选项: |
标签 |
通过设置标签,可以将热力图和折线图展示的数据范围限制在满足标签的数据范围内(例如特定层,特定模块类型),包含以下可选类型: |
展示折线图
通过点击热力图中的某个点,即可展示该点对应的精度数据随维度值变化趋势。界面如图所示,具体操作如下表所示。
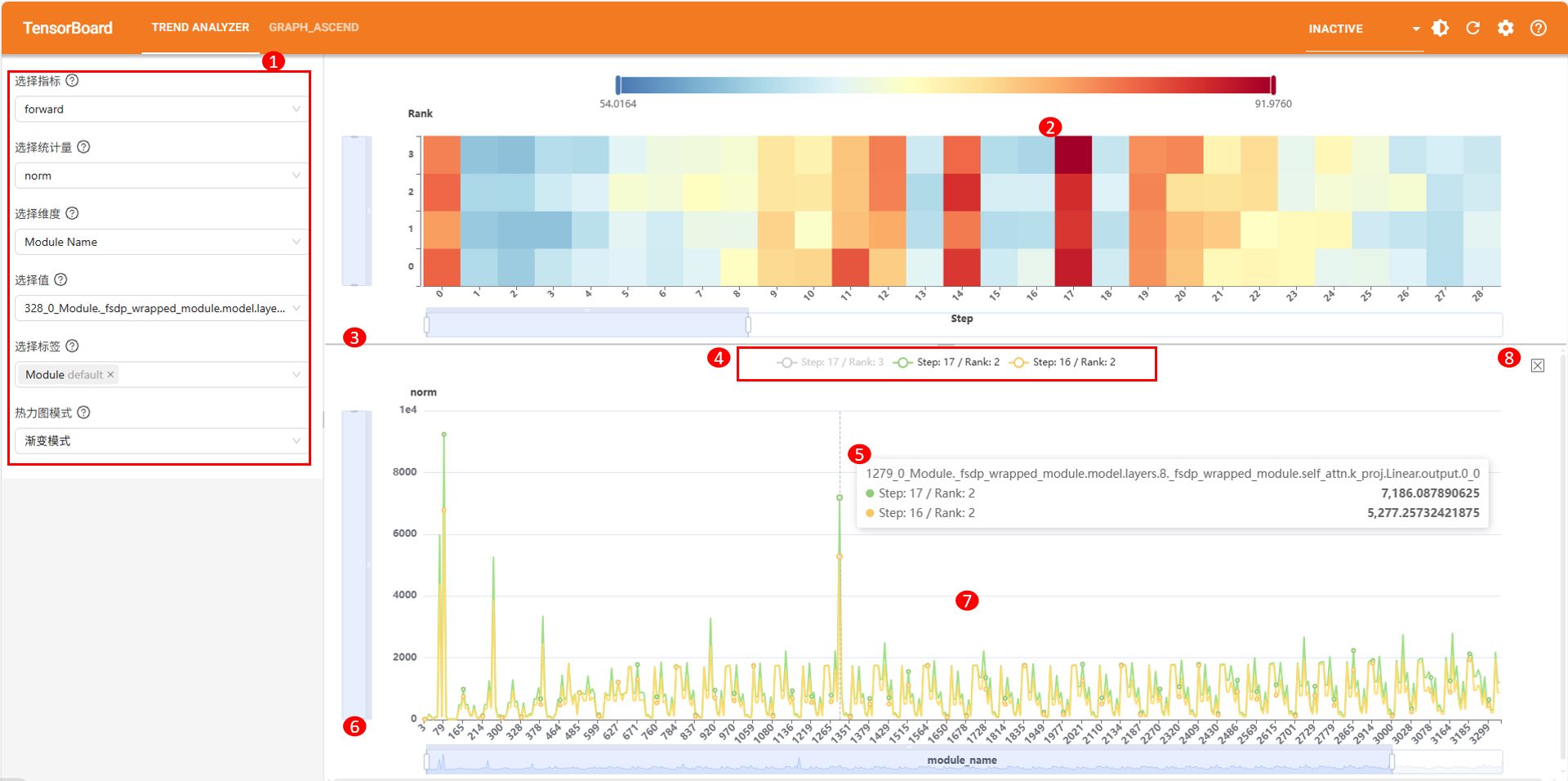
编号 |
说明 |
|---|---|
1 |
按展示热力图选择需要展示数据基本范围,等待热力图加载完毕。 |
2 |
点击热力图中的某个点,展示该点对应的精度数据随维度值变化趋势。可多选,同时加载多条折线,方便比对。 |
3 |
可选,拖动折线图分割线,调整折线图占页面比例。 |
4 |
可选,点击折线图图例,可切换显示或隐藏对应折线。 |
5 |
可选,悬浮在折线图上,展示当前鼠标位置所有折线的具体数据信息。 |
6 |
可选,拖动折线图X轴或Y轴上滑块,调整折线图展示的坐标轴范围。 |
7 |
可选,拖动折线图,或滑动鼠标滚轮,调整折线图展示的X轴范围。 |
8 |
可选,点击清空按钮,清空当前展示的折线图。 |
Megatron模型并行可视化
功能说明
Megatron模型并行可视化是为展示热力图功能提供Megatron模型并行场景各卡网络层与整网位置对应关系可视化能力。
Megatron框架中的模型并行会将模型切分在不同节点rank上。分析精度数据时,各个节点下采集的模型层数据可能仅包含整体模型的部分层,无法直观看出这些层处于整体模型中的位置。Megatron模型并行可视化功能提供多节点模型并行切分的可视化能力,帮助用户快速识别当前模型并行配置下,模型层在各个设备上的分布情况。
注意事项
仅支持Megatron场景下,张量并行、流水线并行、虚拟流水线并行和数据并行模式。
仅支持节点rank数小于等于1024且模型层小于等于256层场景,即需world_size ≤ 1024 且 num_layers ≤ 256。
使用示例
创建Python脚本,以创建的命名为
plot_model.py的脚本为例,将以下代码拷贝到plot_model.py脚本中,并按实际情况修改ParallelConfig中配置。from msprobe.core.common.megatron_utils import ParallelConfig, plot_model_parallelism config = ParallelConfig( world_size=32, num_layers=48, tensor_parallel_size=4, pipeline_parallel_size=4, num_layers_per_virtual_pipeline_stage=3, order="tp-cp-ep-dp-pp", standalone_embedding_stage=False, output_path='./' ) plot_model_parallelism(config)
参数详细介绍请参见plot_model_parallelism接口。
执行如下命令开启转换。
python plot_model.py
输出说明
plot_model_parallelism接口调用成功后,在配置的输出路径output_path中,生成一个png文件, 格式为ws{world_size}_ln{num_layers}_tp{tensor_parallel_size}_pp{pipeline_parallel_size}_vpp{virtual_pipeline_parallel_size}.png。其中virtual_pipeline_parallel_size为根据num_layers_per_virtual_pipeline_stage等传入参数计算出来的虚拟流水线并行分组大小。
浏览png文件,如下图所示:

图片内容介绍:
字段 |
说明 |
|---|---|
Model Parallelism Configuration |
用户设置或计算得来的并行配置信息,包括: |
TP Group |
纵坐标,张量并行分组,形如 |
Virtual Pipeline Stage |
横坐标,流水线并行阶段或虚拟流水线并行阶段,形如 |
Model Copies |
模型副本图例。数据并行中,以不同颜色标记输入数据不同的模型副本。 |
|
图中颜色矩阵上的文字,标识一个张量并行分组下的一个阶段包含哪些模型层,其中: |
附录
mapping配置文件说明
mapping配置文件是为精度数据解析功能的–mapping参数提供数据输入。 配置–mapping参数后,数据解析在处理每个精度数据文件中的模型层的名称或算子名称时,会依次按mapping.json中配置的键、值进行替换。该功能适用于需要精简名称或step间目标名称不一致需对齐的场景。
json文件格式和示例如下,键值均为字符串。
{
".TE": ".",
".MindSeed": "."
}
以上格式中,左侧字段为“键”(如".TE"),右侧字段为“值”(如".“),以上配置代表将名称”.TE"替换为".“,将名称”.MindSeed"替换为"."。
公开接口
plot_model_parallelism
函数原型
plot_model_parallelism(config: ParallelConfig) -> None
参数说明
配置参数实例(ParallelConfig类实例),在实例初始化时传入参数。
参数名 |
输入/输出 |
说明 |
|---|---|---|
world_size |
输入 |
必选参数,模型部署的总rank数,int类型,支持范围为[1, 1024]。 |
num_layers |
输入 |
必选参数,模型的总层数,int类型,支持范围为[1, 256]。 |
tensor_parallel_size |
输入 |
可选参数,张量并行分组大小,int类型,默认值为1。实际训练脚本中指定 |
pipeline_parallel_size |
输入 |
可选参数,流水线并行分组大小,int类型,默认值为1。实际训练脚本中指定 |
num_layers_per_virtual_pipeline_stage |
输入 |
可选参数,每个虚拟流水线阶段包含的层数,int类型,默认值为None,表示未开启虚拟流水线并行。实际训练脚本中指定 |
order |
输入 |
可选参数,模型并行维度的排序顺序,str类型。默认为Megatron默认设置,即 |
standalone_embedding_stage |
输入 |
可选参数,是否开启将嵌入层作为独立的流水线阶段的配置,bool类型,配置True表示开启,False表示关闭,默认值为False。 |
output_path |
输入 |
可选参数,可视化结果输出路径,str类型,默认值为’./'。 |
返回值说明
无
FAQ
如何使用趋势可视化工具对比两组不同实验的精度数据文件?
答:趋势可视化工具并不区分标杆实验和对比实验,仅根据输入的精度数据文件路径进行对比。如需对比两组不同实验的精度数据文件,用户需手动将两组文件子目录移至同一目录,然后使用趋势可视化工具查看和对比。
例如:存在如下两组dump数据文件,dump_path1和dump_path2:
├── dump_path1 │ ├── step0 │ | ├── rank0 │ | | ├── dump.json │ | | ├── stack.json | | | └── construct.json │ | |── rank1 │ ├── step1 ├── dump_path2 │ ├── step0 │ | ├── rank0 │ | |── rank1 │ ├── step1
您可以按追加step的方式将dump_path1和dump_path2子目录移至同一目录:
├── dump_path_compare │ ├── step0 # 原dump_path1的step0 │ ├── step1 # 原dump_path1的step1 │ ├── step2 # 原dump_path2的step0 │ ├── step3 # 原dump_path2的step1
执行命令,获得共4个step的精度数据数据库,此时对比step0和step2的精度数据趋势等同于对比原dump_path1和dump_path2的step0的精度数据趋势:
msprobe data2db --data dump_path_compare --db ./output --format dump
您也可以按追加rank的方式将dump_path1和dump_path2子目录移至同一目录:
├── dump_path_compare │ ├── step0 │ | ├── rank0 # 原dump_path1的step0/rank0 │ | ├── rank1 # 原dump_path1的step0/rank1 │ | ├── rank2 # 原dump_path2的step0/rank0 │ | ├── rank3 # 原dump_path2的step0/rank1 │ ├── step1 │ | ├── rank0 # 原dump_path1的step1/rank0 │ | ├── rank1 # 原dump_path1的step1/rank1 │ | ├── rank2 # 原dump_path2的step1/rank0 │ | ├── rank3 # 原dump_path2的step1/rank1
执行命令,获得共4个rank的精度数据可视化结果,此时对比step0的rank0和rank2的精度数据趋势等同于对比原dump_path1和dump_path2的step0的rank0的精度数据趋势。