Monitor训练状态轻量化监测工具
简介
Monitor训练状态轻量化监测工具,能够在较低性能损耗下收集和记录模型训练过程中的激活值、权重梯度、优化器状态和通信算子的中间值,实时呈现训练状态。
使用前准备
安装
安装msProbe工具,详情请参见《msProbe安装指南》。
约束
PyTorch场景:torch不低于2.1
MindSpore场景:mindspore不低于2.4.10,仅支持MindSpore动态图,支持MSAdapter套件
快速入门
根据需求监测相应对象。比如在loss上扬,grad norm正常的异常训练过程中,优先考虑监测模型前向过程;在grad norm异常的训练过程中,监测权重和激活值的梯度。 推荐使用方式:权重梯度的监测性能损耗小(20B dense模型全量权重梯度监测,时间增加<1%,内存增加<1%),可以长期开启。激活值监测性能损耗大,在必要时开启或者仅监测部分。
配置文件准备
请在当前目录下创建一个config.json文件(配置文件各个字段具体信息请查看详细配置),此处以最常见的权重梯度采集为例:
{
"targets": {},
"wg_distribution": true,
"format": "csv",
"ops": ["min","max", "mean", "norm"],
"ndigits": 16
}
工具使能
在实际训练代码中找到模型、优化器定义完成后、训练开始前的位置,加入工具使能代码,不同场景使能方式如下:
Pytorch使能方式:
# Megatron-LM(core_r0.6.0) training.py
model, optimizer, opt_param_scheduler = setup_model_and_optimizer(model_provider, model_type)
...
# 紧跟着model、optimizer定义完成后即插入monitor工具
+from msprobe.pytorch import TrainerMon
+monitor = TrainerMon(
+ config_file_path="./monitor_config.json",
+ params_have_main_grad=True, # 权重是否使用main_grad,通常megatron类为True,其他为False,默认为True。
+)
+monitor.set_monitor(
+ model,
+ grad_acc_steps=args.global_batch_size//args.data_parallel_size//args.micro_batch_size,
+ optimizer=optimizer
+)
deepspeed与accelerate、transformers同时使用时,optimizer传值方式为optimizer=optimizer.optimizer,若未使用deepspeed,单独使用accelerate、transformers,optimizer传值方式为optimizer=optimizer。
同时使用deepspeed和accelerate时,工具使能位置参考如下:
model, optimizer, trainloader, evalloader, schedular = accelerator.prepare(...)
...
+monitor = TrainerMon(...)
+monitor.set_monitor(....optimizer=optimizer.optimizer)
同时使用deepspeed和transformers时,工具使能位置参考如下:
# src/transformers/trainer.py
class Trainer:
def _inner_training_loop:
...
+ monitor = TrainerMon(...)
+ monitor.set_monitor(....optimizer=self.optimizer.optimizer)
for epoch in range(epochs_trained, num_train_epochs):
...
MindSpore使能方式:
# Megatron-LM(core_r0.6.0) training.py
model, optimizer, opt_param_scheduler = setup_model_and_optimizer(model_provider, model_type)
...
# 紧跟着model、optimizer定义完成后即插入monitor工具
+from msprobe.mindspore import TrainerMon
+monitor = TrainerMon(
+ config_file_path="./monitor_config.json",
+ process_group=None,
+ params_have_main_grad=True, # 权重是否使用main_grad,通常megatron为True,其他为False,默认为True。
+)
# 挂载监测对象
+monitor.set_monitor(
+ model,
+ grad_acc_steps=args.global_batch_size//args.data_parallel_size//args.micro_batch_size,
+ optimizer=optimizer
+)
注意事项
若框架为FSDP1,请先保证model包裹FSDP时设置use_orig_params=True。
训练状态监测工具功能介绍
下表中字段为训练状态轻量化监测工具的完整功能点:
功能 |
说明 |
支持场景 |
|---|---|---|
开启权重监测 |
PyTorch、MindSpore |
|
开启权重梯度监测 |
PyTorch、MindSpore |
|
开启激活值监测 |
PyTorch、MindSpore |
|
开启优化器状态监测 |
PyTorch、MindSpore |
|
采集监测的第一个 step 的 module 对应的堆栈信息辅助问题定位 |
PyTorch、MindSpore |
|
指定监测的nn.Module(nn.Cell)及对应的输入输出 |
PyTorch、MindSpore |
|
打印模型结构 |
PyTorch |
|
开启模型状态的高阶监测 |
PyTorch、MindSpore |
|
开启梯度监测时,采集聚合前梯度时支持 |
PyTorch、MindSpore |
|
监测对象指标异常时自动告警,支持异常数据落盘 |
PyTorch、MindSpore |
|
将csv转为tensorboard文件显示 |
PyTorch |
|
训练过程中动态修改配置开启监测 |
PyTorch、MindSpore |
|
训练中开启激活值监测。待废弃,请使用动态启停功能代替。 |
PyTorch |
权重监测
该功能可开启权重监测,工具配置示例:
{
"targets": {
},
"param_distribution": true,
"format": "csv",
"ops": ["norm", "min", "max", "nans"]
}
targets中指定module包含的所有权重都会被监测。targets为空时,默认监测全部module。
设置param_distribution为true,表示开启权重监测功能,默认值为false。
权重梯度监测
该功能可开启权重梯度监测,监测聚合前后的权重梯度,工具配置示例:
{
"targets": {
},
"wg_distribution": true,
"format": "csv",
"ops": ["norm", "min", "max", "nans"]
}
targets中指定module包含的所有权重都会被监测。targets为空时,默认监测全部module。
设置wg_distribution(weight grad, noted as wg) 为true,表示开启权重梯度监测功能,默认值为false。
激活值监测
该功能可开启激活值监测,工具配置示例:
{
"targets": {
},
"xy_distribution": true,
"forward_only": false,
"backward_only": false,
"all_xy": true,
"format": "csv",
"ops": ["norm", "min", "max", "nans"]
}
all_xy为true表示监测全量module激活值,若需要对指定模块设置监测对象,在targets中进行配置,配置方式参考 指定监测对象 。
设置xy_distribution为true表示开启激活值监测功能,默认值为false。
注意:forward_only和backward_only均为true时,触发warning,前反向均不采集;默认值均为false时,前反向均采集。
优化器状态监测
该功能可开启优化器状态监测,工具配置示例:
{
"targets": {
},
"mv_distribution": true,
"format": "csv",
"ops": ["norm", "min", "max", "nans"]
}
targets中指定module包含的所有权重都会被监测。targets为空时,默认监测全部module。
设置mv_distribution为true表示开启优化器状态监测功能(1st moment noted as m, 2nd moment noted as v),默认值为false。什么是mv
本工具针对分布式计算框架megatron和deepspeed框架做了适配,暂不支持其他框架。
采集module堆栈信息
该功能可采集module堆栈详细信息,工具配置示例:
{
"targets": {
},
"format": "csv",
"stack_info": true
}
开启 stack_info 后会采集监测的第一个 step 的所有 module 的堆栈信息,输出格式仅支持 csv 。
指定监测对象
工具支持对指定nn.Module进行状态监测,在配置文件的targets字段中指定,targets格式为{module_name: {}}。
module_name可以通过nn.Module的接口named_modules()获取。
打印模型结构
工具提供可选项print_struct打印模型结构,帮助配置targets。工具会在在第一个step后打印结构并停止训练进程,每张卡上的模型结构默认保存在$MONITOR_OUTPUT_DIR/module_struct/rank{rank}/module_struct.json, 其中{rank}为对应的卡号。
{
"print_struct": true
}
输出样例:
"0:63.mlp.linear_fc2": {
"input": {
"config": "tuple[1]",
"0": "size=(4096, 4, 1024), dtype=torch.bfloat16"
},
"output": {
"config": "tuple[2]",
"0": "size=(2048, 4, 512), dtype=torch.bfloat16",
"1": "size=(512,), dtype=torch.bfloat16"
},
"input_grad": {
"config": "tuple[1]",
"0": "size=(4096, 4, 1024), dtype=torch.bfloat16"
},
"output_grad": {
"config": "tuple[2]",
"0": "size=(2048, 4, 512), dtype=torch.bfloat16",
"1": "size=(512,), dtype=torch.bfloat16"
}
},
对于module对象,通常关心前向/反向传播的输入和输出:
前向的输入(input)
前向的输出(output)
反向的输入,表示前向输出的梯度(output_grad)
反向的输出,表示前向输入的梯度(input_grad)
指定监测对象
targets字段指定监测对象示例如下:
// 示例:对一个名为"module.encoder.layers.0.mlp"的module。
"targets": {
"module.encoder.layers.0.mlp": {}
}
对于parameter对象,通常会关注其在一个训练迭代中的梯度(weight grad)、adam类优化器中的动量(1st moment, 2nd moment)。 parameter归属于某一module,可以通过指定module_name来监测包含在这一module中的所有parameter。
param_name可以通过nn.Module的接口named_parameters()获取。
// 示例:监测"module.encoder.layers.0.mlp"的所有参数和"module.embedding.word_embedding.weight"这一参数
{
"targets": {
"module.encoder.layers.0.mlp": {},
"module.embedding.word_embedding.weight": {}
}
}
全量监测
工具提供简便的全量module对象监测方式。
{
"targets": {}
}
l2可解释特征监测
该功能可开启模型状态的高阶监测,工具配置示例:
{
"l2_targets": {
"attention_hook": ["0:0.self_attention.core_attention.flash_attention"],
"linear_hook": ["0:0.self_attention.linear_qkv", "0:1.self_attention.linear_qkv"]
},
"recording_l2_features": true,
"sa_order": "b,s,h,d"
}
配置项 |
可选/必选 |
类型 |
说明 |
|---|---|---|---|
l2_targets |
必选 |
Dict[str, List[str]] |
指定需要监测的模型层配置 |
recording_l2_features |
可选 |
bool |
是否开启L2层特征数据采集,默认为false表示不采集 |
sa_order |
可选 |
str |
计算 |
L2可解释特征监测指标说明
指标名称 |
适用Hook类型 |
数学定义/计算方式 |
监测意义 |
|---|---|---|---|
entropy |
attention_hook |
\(H(p)=-\sum p_i \log p_i\),其中\(p_i\)为注意力权重 |
衡量注意力分布的不确定性,低熵值表示注意力集中 |
softmax_max |
attention_hook |
\(\max(\text{softmax}(QK^T/\sqrt{d}))\) |
反映注意力机制的聚焦程度,高值表示存在显著主导的注意力token |
sr(stable_rank) |
linear_hook |
\(\frac{|W|_F}{|W|_2}\)(稳定秩,Frobenius范数除以谱范数) |
评估权重矩阵的有效秩,低值表示矩阵接近低秩不稳定状态 |
kernel_norm |
linear_hook |
\(|W|_F\)(Frobenius范数) |
权重矩阵的缩谱范数,反映输入在矩阵最大奇异向量张成空间的放大系数 |
mbs粒度梯度监测
当配置梯度监测任务时,工具默认global_batch_size粒度进行梯度监测。当需要监测micro_batch_size粒度梯度信息时,在配置文件中配置monitor_mbs_grad为true,配置示例如下:
{
"wg_distribution": true,
"monitor_mbs_grad": true
}
应用范围
仅支持采集聚合前梯度,在梯度累积场景下,聚合后梯度已无法区分
micro_batch数据。PyTorch场景下,Megatron和DeepSpeed训练框架下均支持,FSDP训练框架下暂不支持。
MindSpore场景下均支持。
异常告警
工具的异常告警功能旨在自动判断训练过程中的异常现象,用户可通过在配置文件中配置alert字段来指定告警规则,并在训练过程中根据该规则及时打印告警信息。
异常告警规则
当前支持的异常告警规则如下:
异常告警 |
解释 |
rule_name |
args是否可选 |
|---|---|---|---|
历史均值偏离告警 |
将当前数值与历史均值比较。如果相对偏差超过阈值,会在打印信息中提示用户指标偏离。当前仅对 |
AnomalyTurbulence |
否,必须传入threshold。当指标超过 |
nan值/极大值告警 |
根据是否提供threshold来判断nan值或极大值 |
AnomalyNan |
是, 若未配置args或未配置threshold,则默认检测nan,若提供threshold,则检测nan值以及绝对值超过阈值的极大值 |
除此之外,我们在alert中支持dump配置项,如果打开"dump"选项,则会将异常信息落盘到目录monitor_output/anomaly_detected。
历史均值偏离告警案例如下:
"alert": {
"rules": [{"rule_name": "AnomalyTurbulence", "args": {"threshold": 0.5}}], // 0.5表示偏离50%则提示偏离
"dump": true
},
nan值/极大值告警案例如下:
"alert": {
"rules": [{"rule_name": "AnomalyNan", "args": {"threshold": 1e10}}],
"dump": true
},
注:当配置多条异常告警规则时,优先告警第一条,如以下配置时每一层会优先报AnomalyNan的告警(一般不建议配置多条规则):
"alert": {
"rules": [
{"rule_name": "AnomalyNan", "args": {"threshold": 1e10}},
{"rule_name": "AnomalyTurbulence", "args": {"threshold": 0.5}}
],
"dump": true
},
异常提示说明
训练过程中,检测到异常后打印提示信息,并将异常信息按照rank分组写入json文件,文件路径默认为monitor_output/anomaly_detected,异常信息示例如下:
{
"0:1.self_attention.core_attention_flash_0/rank0/input_grad_step_1_call_112": {
"rank": 0,
"step": 1,
"micro_step": 0,
"pp_stage": 0,
"vpp_stage": 0,
"call_id": 112,
"tag_name": "0:1.self_attention.core_attention_flash_0/rank0/input_grad",
"message": "Rule AnomalyTurbulence reports anomaly signal in ('0:1.self_attention.core_attention_flash_0/rank0/input_grad', 'min') at step 1.",
"group_mates": [0, 1]
},
...
}
其中call_{xxx}中的xxx为API的执行调用顺序,为后续异常事件排序做准备。
异常事件排序
当模型训练过程中出现较多异常数据,需要对异常事件排序。工具提供topk的异常排序能力,按照api的执行顺序进行排序,便于定界首次异常点。异常分析命令示例:
python3 -m msprobe.core.monitor.anomaly_processor -d $MONITOR_OUTPUT_DIR/anomaly_detected
异常事件分析结束,将topk事件写入文件anomaly_detected/anomaly_analyse.json。异常分析支持以下参数配置:
参数名称 |
可选/必选 |
说明 |
|---|---|---|
-d 或 --data_path |
必选 |
指定异常落盘文件夹,监测功能输出,一般为$MONITOR_OUTPUT_DIR/anomaly_detected。 |
-o 或 --out_path |
可选 |
排序后的异常落盘文件地址,默认在–data_path路径下落盘一个anomaly_analyse.json文件。 |
-k 或 --topk |
可选 |
指定保留前topk个异常,默认为8。 |
-s 或 --step_list |
可选 |
指定分析的step范围,默认为[]。 |
csv格式数据转tensorboard可视化显示
将csv数据转换为tensorboard格式数据。
from msprobe.pytorch.monitor.csv2tb import csv2tensorboard_by_step
# 前三个参数用来指定需要转换的一批文件,指定monitor输出目录及一个时间范围,会对这个范围内的文件进行转换
# process_num指定拉起的进程个数,默认为1,更多的进程个数可以加速转换
# data_type_list是一个列表,指定需要转换的数据类型,默认转换全部数据,数据类型应来自输出件文件前缀,所有类型数据:
# ["actv", "actv_grad", "exp_avg", "exp_avg_sq", "grad_unreduced", "grad_reduced", "param_origin", "param_updated"]
# output_dirpath可指定输出目录,默认保存到"{curtime}_csv2tensorboard_by_step"文件夹,其中curtime为自动获取的当前时间戳
csv2tensorboard_by_step(
monitor_path="~/monitor_output", # 必填
time_start="Dec03_21-34-40", # 必填
time_end="Dec03_21-34-42", # 必填
process_num=8,
data_type_list=["param_origin"]
)
参数详细介绍请参见公开接口的“csv输出件转tensorboard输出件”
动态启停
动态启停模式:支持用户在训练过程中随时启动/更新监测。
用户可在训练开始前通过配置环境变量DYNAMIC_MONITOR=True来确认进入动态启停模式,该模式下需要配合config.json文件中的dynamic_on字段来使用。
在动态启停模式下,启动和停止分别由如下控制:
启动:
首次监测:查看config.json文件中
dynamic_on字段,若为true则在下一步开启监测。非首次监测:查看config.json文件时间戳,若时间戳更新且config.json文件中
dynamic_on字段为true则在下一步开启监测。
停止: 到达
collect_times之后自动停止并修改config.json文件中dynamic_on字段为false,可再通过上述操作重启。
注意事项::
默认监测启动皆统一在配置初始化或查询到更新后的下一步,即第n步挂载hook将在第n+1步启动采集,如需采集第0步数据请使用静态模式。
config.json中途修改错误时,若此时不在监测则不生效,若在监测则用原配置继续。
达到
collect_times之后程序会自动将该值置为false,待下次修改为true时重启。
支持的使用场景说明如下:
场景 |
监测模式 |
操作步骤 |
结果描述 |
|---|---|---|---|
场景1: 使用默认静态模式 |
静态 |
1. 配置环境变量: |
走默认分支进行数据采集和保存,不受config.json中 |
场景2: 进入动态启停模式,初始不启动监测 |
动态 |
1.配置环境变量: |
初始状态下无监测,不进行数据采集和保存 |
场景3: 进入动态启停模式,初始即启动监测 |
动态 |
1.配置环境变量: |
根据初始配置在第1步(初始计数为0)开启监测并保存,采集 |
场景4: 进入动态启停模式,初始暂不启动监测,训练中途启动 |
动态 |
1.配置环境变量: |
训练中途根据最新配置在下一步开启监测并保存,采集 |
场景5: 进入动态启停模式,监测还未结束时中途修改config.json采集配置 |
动态 |
1.配置环境变量: |
更新前按旧配置采集并保存,更新后下一步以最新config.json采集且 |
场景6: 进入动态启停模式,在根据 |
动态 |
1.配置环境变量: |
更新前按旧配置采集并保存,中途停止监测后无采集,重启后下一步以最新config.json重启采集且 |
功能重载
此功能将在2026年废弃。请使用动态启停功能代替。
统计量 可以在训练过程中修改
TrainerMon实例的ops属性, 调整监测的统计量。
if {some condition}:
monitor.ops = ["min", "max"]
训练过程中开关激活值监测 激活值监测的性能损耗较大, 推荐仅在必要时开启, 比如发现loss出现尖刺, 根据loss的异常开启激活值监测.
if {some condition}:
monitor.reload_xy(xy_distribution=True)
输出结果
输出路径
通过环境变量MONITOR_OUTPUT_DIR设置monitor输出路径,默认为./monitor_output/。
export MONITOR_OUTPUT_DIR=/xxx/output_dir
输出格式
通过可选配置项format指定,当前仅支持csv(默认值)。
csv 监测结果写入csv文件中,可以通过
ndigits字段设置小数位数。
表头为 vpp_stage | name | step | micro_step(optional) | *ops |。 仅在激活值监测的输出文件中包含micro_step。 激活值监测的name为<module_name>.<input or output>, 其他任务的name为<param_name>。
如需将csv转为tensorboard格式进行可视化,可使用csv格式数据转tensorboard可视化显示功能。
csv输出件合并
提供csv输出件合并功能,在配置json文件中设置step_count_per_record,表示每个csv文件存储多个step的监测数据。默认值为1,表示每个csv文件记录一个step的监测数据。
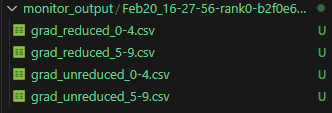
如下图所示为梯度监测结果示例,配置step_count_per_record为5,连续监测10个step,每个csv文件记录了5个step的梯度数据。其中grad_reduced_0-4.csv为step0至step4共计5个step的聚合后梯度数据,grad_unreduced_0-4.csv为step0至step4共计5个step的聚合前梯度数据。
公开接口
monitor工具初始化
TrainerMon.__init__(config_file_path, process_group=None, params_have_main_grad=True) -> None
参数 |
可选/必选 |
说明 |
|---|---|---|
config_file_path |
必选 |
json配置文件路径。 |
process_group |
可选 |
传入ProcessGroup对象,用以确定pipeline并行不同rank异常间时序,megatron下通过core.parallel_state.get_pipeline_model_parallel_group()获得。仅在异常时序判断功能中使用。 |
params_have_main_grad |
可选 |
权重是否使用main_grad,通常megatron为True,deepspeed为False。默认为True。 |
opt_ty(该参数废弃) |
可选 |
表示优化器类型。 |
模型挂载monitor工具
TrainerMon.set_monitor(model, grad_acc_steps, optimizer, dp_group=None, tp_group=None, start_iteration=0) -> None
参数 |
可选/必选 |
说明 |
|---|---|---|
model |
必选 |
需要监测的模型,需要是一个torch.nn.Module或者mindspore.nn.Cell。 |
grad_acc_steps |
必选 |
梯度累积步数。 |
optimizer |
必选 |
需要patch的优化器。 |
dp_group |
可选 |
数据并行的通信组。 |
tp_group |
可选 |
张量并行的通信组。 |
start_iteration |
可选 |
训练的起始iteration,影响工具计数。仅PyTorch场景支持此参数。 |
csv输出件转tensorboard输出件
csv2tensorboard_by_step(monitor_path, time_start, time_end, process_num=1, data_type_list=None) -> None
参数 |
可选/必选 |
说明 |
|---|---|---|
monitor_path |
必选 |
待转换的csv存盘目录。 |
time_start |
必选 |
起始时间戳。搭配time_end一起使用。指定一个时间范围,会对这个范围内的文件进行转换。左闭右闭的区间。 |
time_end |
必选 |
结束时间戳。搭配time_start一起使用。指定一个时间范围,会对这个范围内的文件进行转换。左闭右闭的区间。 |
process_num |
可选 |
指定拉起的进程个数,默认为1,更多的进程个数可以加速转换。 |
data_type_list |
可选 |
指定需要转换的数据类型, 数据类型应来自输出件文件前缀,所有类型数据: |
output_dirpath |
可选 |
指定转换后的输出路径,默认输出到"{curtime}_csv2tensorboard_by_step"文件夹,其中curtime为自动获取的当前时间戳。 |
在模型任意位置获取当前参数梯度统计量
TrainerMon.generate_wgrad_metrics() -> tuple[dict, dict]
具体使用方式如下:
reduced, unreduced = monitor.generate_wgrad_metrics()
在模型任意位置获取当前参数激活值统计量
TrainerMon.generate_xy_metrics() -> tuple[dict, dict]
具体使用方式如下:
actv, actv_grad = monitor.generate_xy_metrics()
老版接口说明, 将在2026年废弃:
TrainerMon.set_wrapped_optimizer(optimizer) -> None
参数 |
可选/必选 |
说明 |
|---|---|---|
optimizer |
必选 |
megatron、deepspeed创建好的混合精度优化器 |
TrainerMon.monitor_gnorm_with_ad(model, grad_acc_steps, optimizer, dp_group, tp_group, start_iteration) -> None
参数 |
可选/必选 |
说明 |
|---|---|---|
model |
必选 |
需要监测的模型,需要是一个torch.nn.Module或者mindspore.nn.Cell。 |
grad_acc_steps |
必选 |
梯度累积步数。 |
optimizer |
可选 |
需要patch的优化器。 |
dp_group |
可选 |
数据并行的通信组。 |
tp_group |
可选 |
张量并行的通信组。 |
start_iteration |
可选 |
训练的起始iteration,影响工具计数。仅PyTorch场景支持此参数。 |
具体接口变更说明如下:
变更 |
说明 |
|---|---|
初始化接口统一精简 |
TrainerMon.init(config_file_path, process_group=None, param_have_main_grad=True) |
主调接口修改 |
从monitor_gnorm_with_ad(…)改名为set_monitor(…), 且此时optimizer从可选项改为必传项 |
优化器包装接口废除 |
set_wrapped_optimizer接口废除, optimizer传入由set_monitor主调完成 |
详细配置
{
"targets": {
"language_model.encoder.layers.0": {"input": "tuple[2]:0", "output": "tensor", "input_grad":"tuple[2]:0", "output_grad":"tuple[1]:0"}
},
"dynamic_on": false,
"start_step": 0,
"collect_times": 100000000,
"step_interval": 1,
"print_struct": false,
"module_ranks": [0,1,2,3],
"ur_distribution": true,
"xy_distribution": true,
"all_xy": true,
"forward_only": false,
"backward_only": false,
"mv_distribution": true,
"param_distribution": true,
"wg_distribution": true,
"monitor_mbs_grad": true,
"cc_distribution": {"enable":true, "cc_codeline":[]},
"alert": {
"rules": [{"rule_name": "AnomalyTurbulence", "args": {"threshold": 0.5}}],
"dump": false
},
"format": "csv",
"ops": ["min", "max", "norm", "zeros", "nans", "mean"],
"eps": 1e-8,
"ndigits": 12,
"step_count_per_record": 1,
"append_output": [],
"squash_name": false
}
下面详细解释各个字段:
字段名字 |
可选/必选 |
解释 |
|---|---|---|
“targets” |
可选 |
指定需要监测的模型层和监测对象, 例如transformer的第0层language_model.encoder.layers.0,可选择监测input、output、input_grad、output_grad。如果不清楚模型结构, 可以将 “print_struct” 字段设置为 true, 监测工具会打印模型中torch module的名字和详细结构,并在第1个step后退出。未配置时默认为全量监测。 |
“input” |
可选 |
"tuple[2]:0"的意思是目标module的前向input参数为长度为2的tuple, 我们关心的是tuple第0个元素。 |
“output” |
必选 |
"tensor"的意思是目标module的前向output参数类型为tensor |
“input_grad” |
可选 |
"tuple[2]:0"的意思是目标module的后向input_grad参数是长度为2的tuple, 我们关心的是tuple的第0个元素。 |
“output_grad” |
必选 |
"tuple[1]:0"的意思是目标module的后向output_grad参数是长度为1的tuple, 我们关心的是tuple的第0个元素。 |
“dynamic_on” |
可选 |
在动态启停时使用,true代表打开监测,false代表关闭监测,默认值为false,且达到collect_times之后会自动将该值置为false,待下次修改为true时重启。 |
“collect_times” |
可选 |
设置采集次数,达到该次数后停止监测,默认值为100000000,目的是一直采集。 |
“start_step” |
可选 |
设置开始采集step,模型训练达到start_step后开始监测采集,默认值为0,表示从step0开始监测采集。注:在动态启停模式下该设置不生效,只会从下一步开始监测采集。 |
“step_interval” |
可选 |
设置采集step间隔,默认值为1,表示每个step均采集监测数据。 |
“print_struct” |
可选 |
设置为true后监测工具会打印每张卡模型中module的名字和详细结构,并在第1个step后退出。不填默认为false。 |
“module_ranks” |
可选 |
用于在分布式训练场景中希望控制在哪些rank开启module监测。如果不填,则默认在所有rank开启。 列表内rank要求为int类型。 |
“ur_distribution” |
可选 |
若为true则会统计adam优化器指定模块(targets中指定)参数的update和ratio向量的数值分布,并展示在heatmap里。默认为false。 |
“xy_distribution” |
可选 |
若为true则会监测指定module(targets中指定)的输入输出张量。 默认为false。 |
“all_xy” |
可选 |
开启xy_distribution后生效,若为true,监测所有module。默认为false。 |
“forward_only” |
可选 |
开启xy_distribution后生效,若为true,仅监测指定module的前向,targets中的input_grad、output_grad不生效。默认为false。 |
“backward_only” |
可选 |
开启xy_distribution后生效,若为true,仅监测指定module的反向,targets中的input、output不生效。默认为false。 |
“mv_distribution” |
可选 |
若为true则会监测指定模块中的参数的优化器状态, 默认为false。 |
“wg_distribution” |
可选 |
若为true则会监测指定模块的参数梯度, 默认为false。 |
“monitor_mbs_grad” |
可选 |
若为true则会监测mbs粒度梯度统计量,默认为false。 |
“param_distribution” |
可选 |
若为true则会监测指定模块的参数, 默认为false。 |
“alert” |
可选 |
“rules”: 指定自动报警的异常检测机制及其相应的阈值。目前实现的异常检测是AnomalyTurbulence, 如果统计标量超出历史均值的指定浮动范围(threshold 0.5意味着上浮或者下浮50%)则在控制台打印报警信息。当"dump"字段配置为true表示异常事件写入文件,默认为false。仅PyTorch场景支持此参数。 |
“cc_distribution” |
可选 |
其中"enable"字段控制通信监测模块的开关,仅支持在多卡训练时开启;需要监测通信算子时,务必尽量早地实例化 |
“mg_direction” |
可选 |
若为true则会计算权重梯度和动量方向一致的比例,默认为false。 |
“format” |
可选 |
数据落盘格式,仅支持"csv"(默认值)。 |
“ops” |
可选 |
类型为list,与ur_distribution、xy_distribution、mv_distribution、wg_distribution、mg_direction、cc_distribution配合,监测所选张量的统计指标,目前支持"min"、“max”、“norm”、“mean”、“zeros”、“nans”。其中,zeros代表监测所选张量的元素小于eps的比例,nans代表张量中nan的数量。当ops中无有效指标时,默认监测norm指标。 |
“eps” |
可选 |
若ops里包含"zeros"则需要配置,默认为1e-8。 |
“ndigits” |
可选 |
"format"为"csv"时,设置落盘文件中的小数位数,默认为6。 |
“step_count_per_record” |
可选 |
"format"为"csv"时生效,每个csv记录多少个step的数据,默认为1。 |
“append_output” |
可选 |
适用于断点续训场景。多卡场景下生效,指定两个时间戳,将输出续写到这两个时间戳范围间的输出件中,不在范围内的rank不被续写。时间戳应来自原有输出件目录前缀,例如[“Dec03_21-34-40”, “Dec03_21-34-41”]。默认为[],不续写。仅PyTorch场景支持此参数。 |
“squash_name” |
可选 |
是否简化参数名/模块名,多模态场景建议关闭,默认为False。 |